A new study by researchers at MIT and Massachusetts General Hospital (MGH) suggests the day may be approaching when advanced artificial intelligence systems could assist anesthesiologists in the operating room.
In a special edition of Artificial Intelligence in Medicine, the team of neuroscientists, engineers, and physicians demonstrated a machine learning algorithm for continuously automating dosing of the anesthetic drug propofol. Using an application of deep reinforcement learning, in which the software’s neural networks simultaneously learned how its dosing choices maintain unconsciousness and how to critique the efficacy of its own actions, the algorithm outperformed more traditional software in sophisticated, physiology-based simulations of patients. It also closely matched the performance of real anesthesiologists when showing what it would do to maintain unconsciousness given recorded data from nine real surgeries.
The algorithm’s advances increase the feasibility for computers to maintain patient unconsciousness with no more drug than is needed, thereby freeing up anesthesiologists for all the other responsibilities they have in the operating room, including making sure patients remain immobile, experience no pain, remain physiologically stable, and receive adequate oxygen, say co-lead authors Gabe Schamberg and Marcus Badgeley.
“One can think of our goal as being analogous to an airplane’s autopilot, where the captain is always in the cockpit paying attention,” says Schamberg, a former MIT postdoc who is also the study’s corresponding author. “Anesthesiologists have to simultaneously monitor numerous aspects of a patient’s physiological state, and so it makes sense to automate those aspects of patient care that we understand well.”
Senior author Emery N. Brown, a neuroscientist at The Picower Institute for Learning and Memory and Institute for Medical Engineering and Science at MIT and an anesthesiologist at MGH, says the algorithm’s potential to help optimize drug dosing could improve patient care.
“Algorithms such as this one allow anesthesiologists to maintain more careful, near-continuous vigilance over the patient during general anesthesia,” says Brown, the Edward Hood Taplin Professor Computational Neuroscience and Health Sciences and Technology at MIT.
Both actor and critic
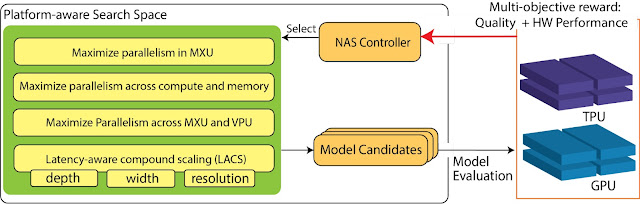
The research team designed a machine learning approach that would not only learn how to dose propofol to maintain patient unconsciousness, but also how to do so in a way that would optimize the amount of drug administered. They accomplished this by endowing the software with two related neural networks: an “actor” with the responsibility to decide how much drug to dose at every given moment, and a “critic” whose job was to help the actor behave in a manner that maximizes “rewards” specified by the programmer. For instance, the researchers experimented with training the algorithm using three different rewards: one that penalized only overdosing, one that questioned providing any dose, and one that imposed no penalties.
In every case, they trained the algorithm with simulations of patients that employed advanced models of both pharmacokinetics, or how quickly propofol doses reach the relevant regions of the brain after doses are administered, and pharmacodynamics, or how the drug actually alters consciousness when it reaches its destination. Patient unconsciousness levels, meanwhile, were reflected in measure of brain waves, as they can be in real operating rooms. By running hundreds of rounds of simulation with a range of values for these conditions, both the actor and the critic could learn how to perform their roles for a variety of kinds of patients.
The most effective reward system turned out to be the “dose penalty” one in which the critic questioned every dose the actor gave, constantly chiding the actor to keep dosing to a necessary minimum to maintain unconsciousness. Without any dosing penalty the system sometimes dosed too much, and with only an overdose penalty it sometimes gave too little. The “dose penalty” model learned more quickly and produced less error than the other value models and the traditional standard software, a “proportional integral derivative” controller.
An able advisor
After training and testing the algorithm with simulations, Schamberg and Badgeley put the “dose penalty” version to a more real-world test by feeding it patient consciousness data recorded from real cases in the operating room. The testing demonstrated both the strengths and limits of the algorithm.
During most tests, the algorithm’s dosing choices closely matched those of the attending anesthesiologists after unconsciousness had been induced and before it was no longer necessary. The algorithm, however, adjusted dosing as frequently as every five seconds, while the anesthesiologists (who all had plenty of other things to do) typically did so only every 20-30 minutes, Badgeley notes.
As the tests showed, the algorithm is not optimized for inducing unconsciousness in the first place, the researchers acknowledge. The software also doesn’t know of its own accord when surgery is over, they add, but it’s a straightforward matter for the anesthesiologist to manage that process.
One of the most important challenges any AI system is likely to continue to face, Schamberg says, is whether the data it is being fed about patient unconsciousness is perfectly accurate. Another active area of research in the Brown lab at MIT and MGH is in improving the interpretation of data sources, such as brain wave signals, to improve the quality of patient monitoring data under anesthesia.
In addition to Schamberg, Badgeley, and Brown, the paper’s other authors are Benyamin Meschede-Krasa and Ohyoon Kwon.
The JPB Foundation and the National Insititutes of Health funded the study.
source https://news.mit.edu/2022/research-advances-technology-ai-assistance-anesthesiologists-0214